今天又打开了火车头采集器需要更新下网站,可是点了开始后发现错误了。玉是重新修改了列表采集规则。没仔细看等抓完300多个连接导入数据库时发生错了,仔细一看该站的文章列表页将文章url地址做了处理。
表现:
常规的文章列表文章URL应该是 <a href=” https://www.851w.com/url.html “>才对,而该站处理成了<a href=” //www.851w.com.com/url.html “>,就是把协议头https或者http给取消了,这个 在一定程度上是可以防范很多采集程序,软件,爬虫的。采集后的地址列表会多一层网址,就成了 https://www.851w.com/www.851w.com.com/url.html ,这样的话就无法正确采集内容了。
解决方法:
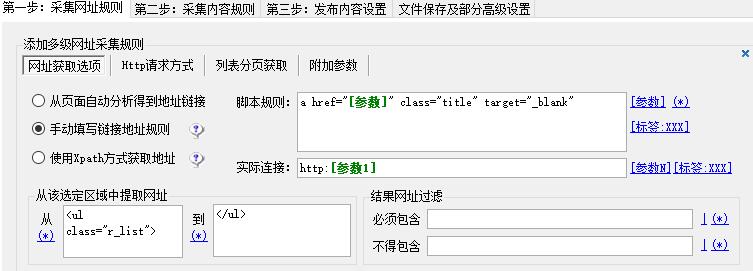
在网址获取选项里点选“手动填写链接地址规则”,
右侧脚本规则填写【a href=”[参数]” class=”title” target=”_blank”】这里的参数就是原始目前的不带协议头的网址。
实际连接:填写【http:[参数1]】如果该网站是https的这里就填写【https:[参数1]】
结果:
以上操作后点获取网址测试正确,从采集,入库等都OK了。
PS:
这个网址问题在SOHU以前看到过,用DEDECMS采集就是网址错误,今天在火车头上总算是解决了。
希望该文能帮助到你。